










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


kd树是什么?kd树的原理【机器学习课程】
更新时间:2022年04月26日14时27分 来源:传智教育 浏览次数:
根据KNN每次需要预测一个点时,我们都需要计算训练数据集里每个点到这个点的距离,然后选出距离最近的k个点进行投票。当数据集很大时,这个计算成本非常高。
kd树:为了避免每次都重新计算一遍距离,算法会把距离信息保存在一棵树里,这样在计算之前从树里查询距离信息,尽量避免重新计算。其基本原理是,如果A和B距离很远,B和C距离很近,那么A和C的距离也很远。有了这个信息,就可以在合适的时候跳过距离远的点。
这样优化后的算法复杂度可降低到O(DNlog(N))。感兴趣的读者可参阅论文:Bentley,J.L.,Communications of the ACM(1975)。
1989年,另外一种称为Ball Tree的算法,在kd Tree的基础上对性能进一步进行了优化。感兴趣的读者可以搜索Five balltree construction algorithms来了解详细的算法信息。
kd树原理:
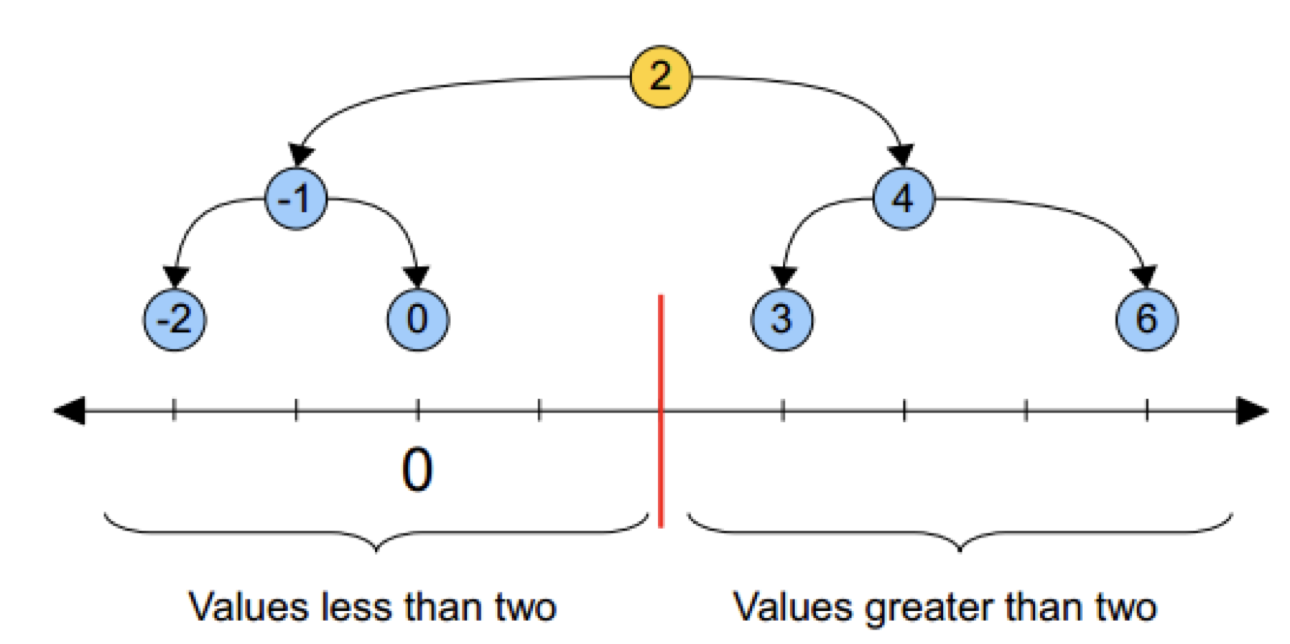
黄色的点作为根节点,上面的点归左子树,下面的点归右子树,接下来再不断地划分,分割的那条线叫做分割超平面(splitting hyperplane),在一维中是一个点,二维中是线,三维的是面。
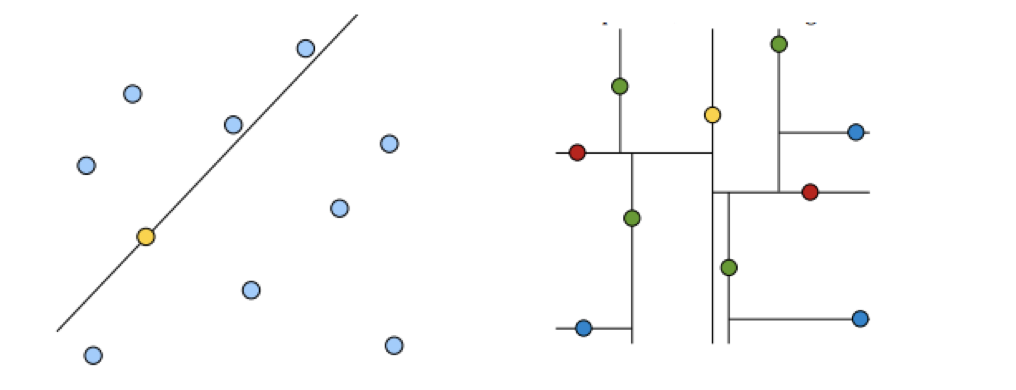
黄色节点就是Root节点,下一层是红色,再下一层是绿色,再下一层是蓝色。
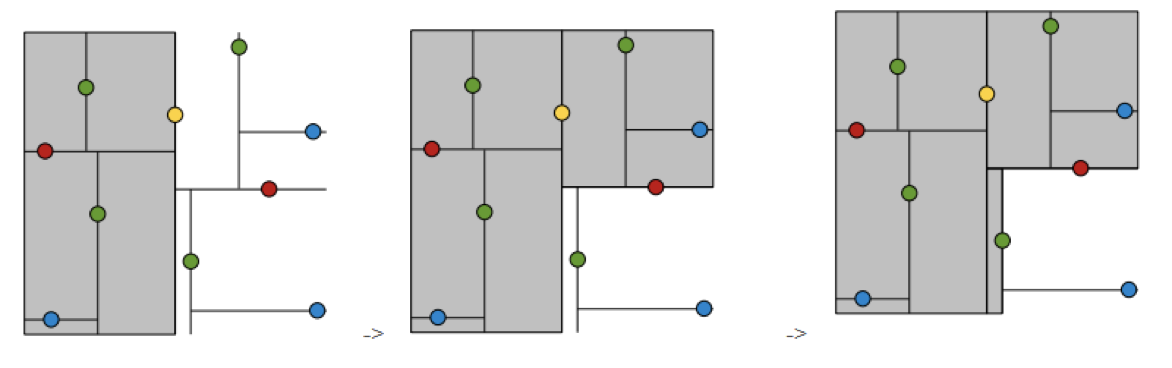
1.树的建立;
2.最近邻域搜索(Nearest-Neighbor Lookup)
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
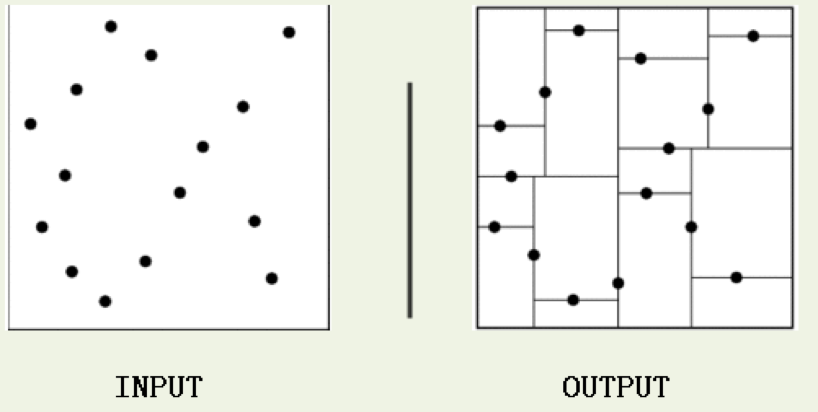
类比“二分查找”:给出一组数据:[9 1 4 7 2 5 0 3 8],要查找8。如果挨个查找(线性扫描),那么将会把数据集都遍历一遍。而如果排一下序那数据集就变成了:[0 1 2 3 4 5 6 7 8 9],按前一种方式我们进行了很多没有必要的查找,现在如果我们以5为分界点,那么数据集就被划分为了左右两个“簇” [0 1 2 3 4]和[6 7 8 9]。
因此,根本就没有必要进入第一个簇,可以直接进入第二个簇进行查找。把二分查找中的数据点换成k维数据点,这样的划分就变成了用超平面对k维空间的划分。空间划分就是对数据点进行分类,“挨得近”的数据点就在一个空间里面。
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
