










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


全部 大数据新闻动态 大数据技术文章 大数据常见问题 技术问答
-
-
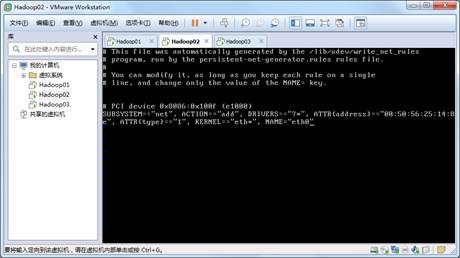
Linux系统安装虚拟机的网络配置方法
虚拟机在安装和克隆之后,虽然能够直接使用,但是此时虚拟机的IP是动态生成的,在不断的开停过程中很容易改变,非常不利于实际开发;通过Hadoop01克隆的虚拟机(假设克隆了2个虚拟机Hadoop02和Hadoop03)则完全无法动态分配到IP,直接无法使用。因此,虚拟机在安装和克隆之后还需要对虚拟机的网络都分别进行配置。 查看全文>>
大数据技术文章2020-12-02 |传智教育 |虚拟机网络配置,Linux系统网络
-
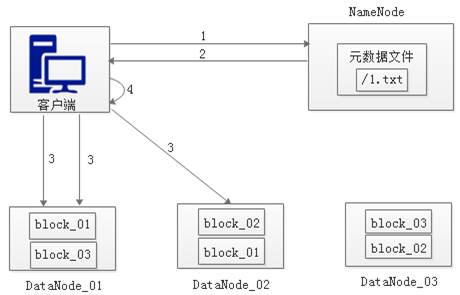
HDFS读写流程介绍,HDFS读数据和写数据的原理是什么?
Client(客户端)对HDFS中的数据进行读写操作,分别是Client从HDFS中查找数据,即为Read(读)数据;Client从HDFS中存储数据,即为Write(写)数据。假设有一个文件1.txt文件,大小为300M,这样就划分出3个数据块,我们根据这三个模块分别讲解HDFS文件读数据和写数据的原理。 查看全文>>
大数据技术文章2020-12-01 |传智教育 |HDFS读写流程,HDFS读写数据的原理
-
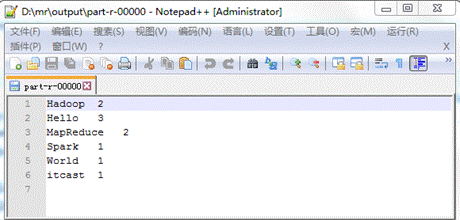
MapReduce程序怎样设置本地运行模式?
MapReduce程序运行模式有本地运行模式和集群运行模式,集群运行模式只需要将MapReduce程序打成Jar包上传至集群即可,下面我们以词频统计为例,讲解如何将MapReduce程序设置为在本地运行模式。 查看全文>>
大数据技术文章2020-12-01 |传智教育 |MapReduce两种运行模式
-

Scala算术操作符重载怎样使用?
Scala算术和操Scala中算术操作符(+、-、*、/、%)的作用和Java是一样的,位操作符(&、|、>>、<<)也是一样的。特别强调的是,Scala的这些操作符其实是方法。例如,a+b其实是a.+(b)的简写,接下来,我们通过Scala交互式Shell编程讲解操作符的使用,具体示例代码如下。 查看全文>>
大数据技术文章2020-11-18 |传智播客 |Scala算术和操符
-

大数据的两种计算框架优劣对比,哪个更适合开发?
Hadoop与Spark两者都是大数据计算框架,但是两者各自都有自己的优势,到底哪个更适合开发使用,下面对两者做一个简单对比: 查看全文>>
大数据技术文章2020-11-18 |传智播客 |Spark与Hadoop对比
-
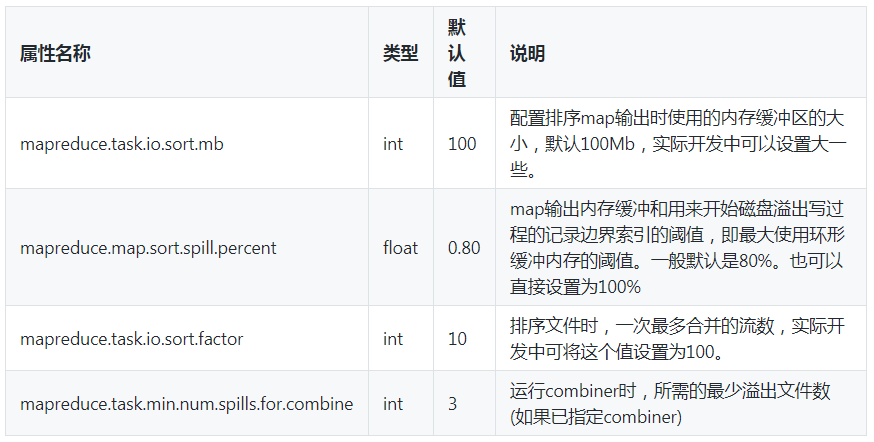
如何操作MapReduce的性能调优?
使用Hadoop进行大数据运算,当数据量极其大时,那么对MapReduce性能的调优重要性不言而喻,尤其是Shuffle过程中的参数配置对作业的总执行时间影响特别大。下面总结一些和MapReduce相关的性能调优方法,主要从五个方面考虑:数据输入、Map阶段、Reduce阶段、Shuffle阶段和其他调优属性。 查看全文>>
大数据技术文章2020-11-18 |传智播客 |MapReduce的性能调优方法
-
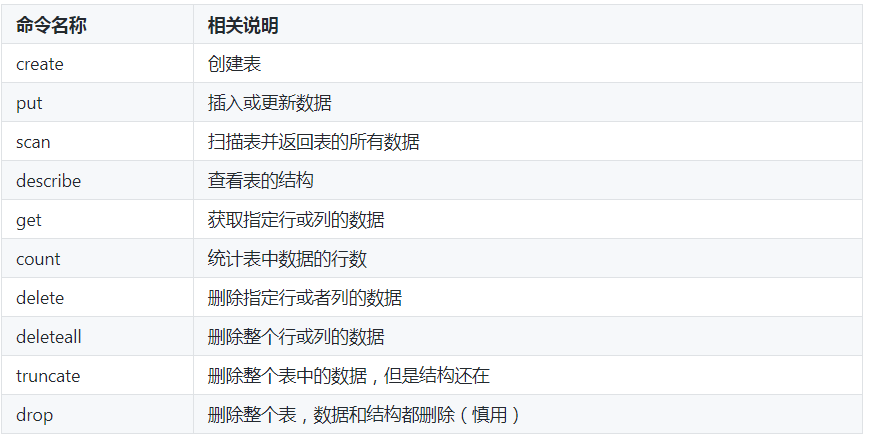
HBase表常见Shell命令及具体语法操作讲解【大数据文章】
Shell命令可以很方便地操作HBase数据库,例如创建、删除及修改表、向表中添加数据、列出表中的相关信息等操作。不过当使用Shell命令行操作HBase时,首先需要进入HBase Shell交互界面,通过一系列Shell命令操作HBase,接下来,通过一张表列举一些操作HBase表常见的Shell命令。 查看全文>>
大数据技术文章2020-11-17 |传智播客 |常见的Shell命令具体是怎样操作的
-
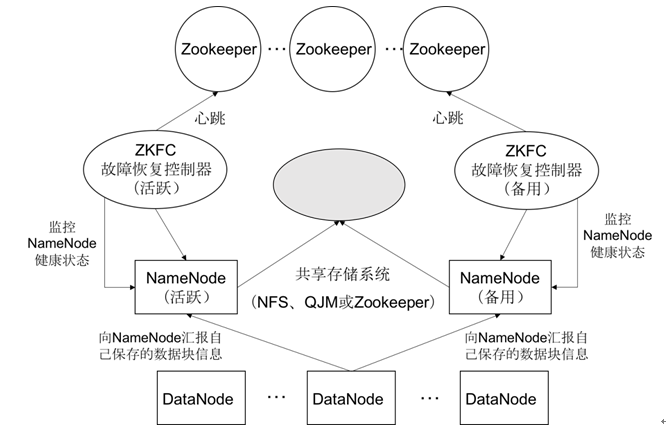
HDFS的高可用架构是怎样工作的?
在Hadoop1.0版本中,NameNode只有一个,一旦这个NameNode发生故障,就会导致整个Hadoop集群不可用,也就是发生了单点故障问题。为了解决单点故障问题,Hadoop2.0中的HDFS中增加了对高可用的支持。 查看全文>>
大数据技术文章2020-11-12 |传智播客 |HDFS高可用架构
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
